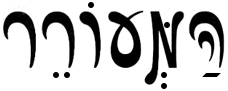


אם הזדמן לכם לעיין בגליונות המעורר, אולי שמתם לב שהם נראים כמו תמונה, אבל ‘מתנהגים’ כמו טקסט חופשי – הם ניתנים לחיפוש מלא ומדויק, וניתן להעתיק את הטקסט מתוכם כמו בקובץ word. מי שרגיל לעבוד עם קבצים סרוקים בשפות לועזיות אולי לא רואה חידוש גדול בדבר, אבל למעשה, טקסט היסטורי ׳חי׳ בעברית הוא לא דבר של מה בכך ונדרשה עבודה רבה כדי להגיע אליו. בשורות הבאות רצינו לשתף אתכם בהיבטים הטכניים של תהליך ההכנה של גליונות המעורר. כפי שתראו, כל אחד ואחת יכולים להשתמש בכלים שבהם השתמשנו, בחינם וללא כל יכולת תכנות.
![]()
טכנולוגיות הקריאה האלקטרונית מתקדמות בצעדי ענק בשנים האחרונות, וזינוק גדול במיוחד נעשה עם המעבר לתוכנות לומדות. כיום, במקום לנסח כללים סבוכים שעל פיהם תזהה התוכנה את תווי הטקסט שבתמונה הסרוקה, נותנים לה דוגמאות של זיהוי נכון, והיא ׳לומדת בעצמה׳.
אם תרצו לקרוא באופן אוטומטי טקסט באנגלית, או בשפה נפוצה אחרת, מתוך תמונה סרוקה, די אם תעלו אותה לכונן הגוגל ותפתחו אותו בתור מסמך. גוגל מנגישים את מנוע ה-OCR- optical character recognition שלו למשתמשים/ות בו, אך כשמדובר בכתב עת היסטורי, שמבנה הדף שלו מורכב, בפרט בשפות נדירות יחסית כמו העברית, ובמיוחד בפונטים היסטוריים שאינם נפוצים עוד, התוצאות יהיו גרועות למדי.
מרבית מפעלי הדיגיטליזציה של ספרים וכתבי עת סרוקים בישראל משתמשים בתכנה המסחרית ABBYY FINE READER, שעד לא מזמן סיפקה את התוצאות המוצלחות ביותר לשפה העברית. בינתיים, בפקולטות למדעי המחשב בארץ ובעולם עומלים המומחים כבר כמה שנים על שיפור האלגוריתמים, אך באקדמיה כמו בתעשייה עיקר המאמצים מופנה לפיתוח עבור שפות נפוצות יותר מעברית, ולחומרי ההווה. כך נותרת העברית ההיסטורית מאחור. יתר על כן, גם אם פותחו עד כה תוכנות בקוד פתוח, היכולת לבצע קריאה אוטומטית בעברית שמורה היתה למי שיכול להפעיל כלי תוכנה דרך שורת הפקודה, וללא ממשק משתמש.

הפלטפורמה ׳טרנסקריבוס׳ מאפשרת מהפכה בתחום: היא זמינה בחינם לכל משתמש/ת פרטי/ת, חוקר/ת או חובב/ת, ומאפשרת לא רק להשתמש בתוכנה הקוראת אלא גם ללמד אותה לקרוא – כל שפה, פונט או אפילו כתב יד, כל עוד נספק לתוכנה דוגמה מספקת.
את גליונות המעורר אנו סורקות במכונות הרגילות שתוכלו למצוא בכל ספריה אקדמית. כדי שהקריאה תהיה מיטבית אנו בוחרות באופצית סריקה ב-600 dpi. את הגליונות הסרוקים אנו טוענים לפלטפורמה של טרנסקריבוס, שם כבר שמור היה לנו מודל קורא עברית, שאומן על גבי טקסטים בעברית מסוגים אחרים. ׳מודל׳ הוא שלב בהתפתחות יכולת הקריאה של התוכנה, שאותו אפשר להחיל על טקסטים חדשים. בנסיונות הראשונים, התכנה זיהתה את הטקסט, אבל כללה שגיאות רבות ביחס למקור. כדי להגיע לטקסט מלא ומדויק כמו שמוצג כאן לפניכם, נדרש עוד שלב.
תלמידות ותלמידי קורס המבוא בתכנית למדעי הרוח הדיגיטליים באוניברסיטת חיפה הכינו את הגליון הראשון: בשלב הראשון, הם תיקנו את הניתוח האוטומטי של מבנה הדף, ובשלב השני תעתקו מספר עמודים באופן ידני.
על בסיס עבודה משותפת זו אפשר היה לאמן את התוכנה לזהות את האותיות בעצמה. כעבודת סיום הקורס, הכינו תלמידות תכנית אופקים טליה שכטר, לורה חוסידמן, ענבר לורבר ומור בן זקן את ״תקן הזהב״: הגרסה המוגהת והמנוקדת של שלש חוברות של המעורר, על גביה אפשר היה לאמן את התוכנה לקרוא טוב בהרבה.

